How VITRO works
VITRO is “model-based”: visual scenarios that shall be presented in images or video sequences are described by abstractions of the real world. We call them “domain models” because usually for each application domain a specific model is needed. The following outlines how, starting with establishing such models, the whole VITRO tool chain operates.
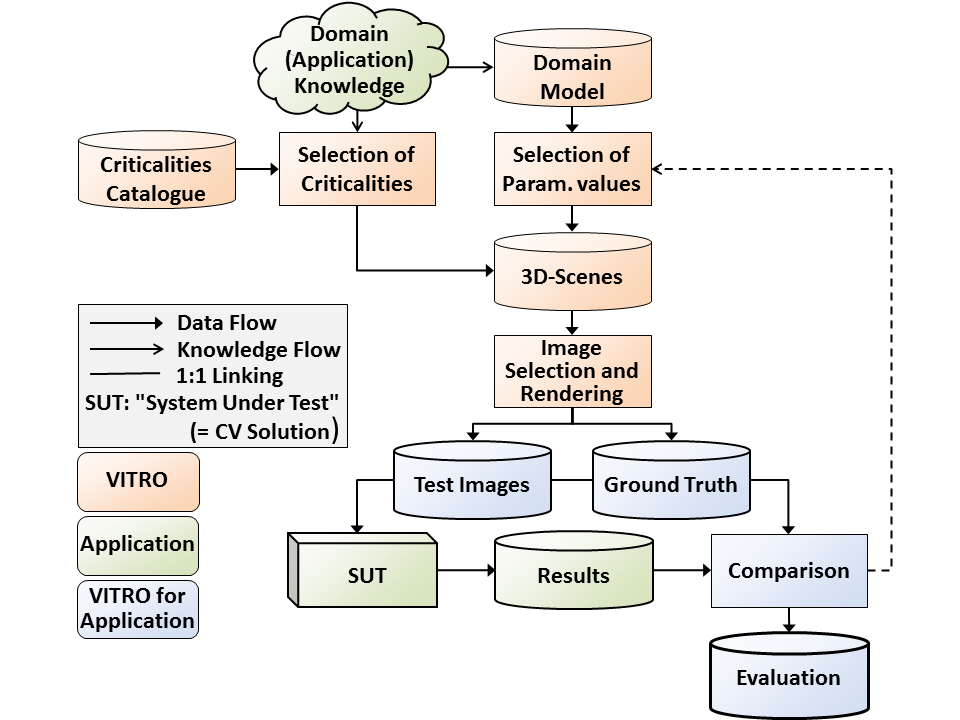 VITRO process flow
VITRO process flow
Modelling. The “domain model” describes the objects (geometry, surface appearance etc.), which can occur in rendered scenes, together with relationships between and constraints on them, as given by the application (e.g. on their size and relative positioning). It also contains information about background, illumination, climatic conditions, and cameras, i.e. the used sensors. For certain families of objects like clouds, generators are available. Further object family generators will be developed on demand.
Criticalities. A catalog with more than a thousand entries is available, which has been created through adaptation of the risk analysis method HAZOP (Hazard and Operability Study) to computer vision (CV). This process has considered light sources, media (e.g. air and climatic phenomena), objects and their interactions (like occlusion and shadow casting), as well as observer effects. The latter includes artifacts of the optics (e.g. aberration), the electronics (e.g. thermal noise), and the software (e.g. compression artifacts). Only application-relevant entries of this catalogue are selected for the actual testing.
Scene generation. The parameters defined in the domain model, e.g. object positions or intensities of light sources, establish a parameter space. This space is sampled with so-called “low geometric discrepancy” which allows achieving the optimal coverage with few sample points. This results in generating scenes typical for the given application. Criticalities are included either by means of further constraints, or their occurrence is checked in generated scenes automatically. For the generation of characteristic curves (see scatter plot), specific scenarios can be defined.
Test data selection and generation. The previous step can yield redundant test images very similar to others. Therefore, test image candidates are characterized with properties derived from their original scenes, e.g. visual fraction of certain objects. These are used to group candidates and select representatives, which are rendered, and finally GT is generated for them. Read more about this under Coverage.
Application. Generated test data can be applied to existing CV solutions for assessing their robustness with respect to the modeled application. But VITRO can already be used during development (e.g. test-driven development). In this case, simple scenes are generated first. Once these are processed robustly, increasingly challenging test data follow iteratively. Finally, adaptive and learning approaches can also be trained and tested.